I Have A Model...Now What?
Suppose we've trained and tuned a classic matrix factorization recommendation model. Let's walk through the series of practical challenges that crop up once you have a model and want to use it to make recommendations to real users.
A first attempt often looks like this:
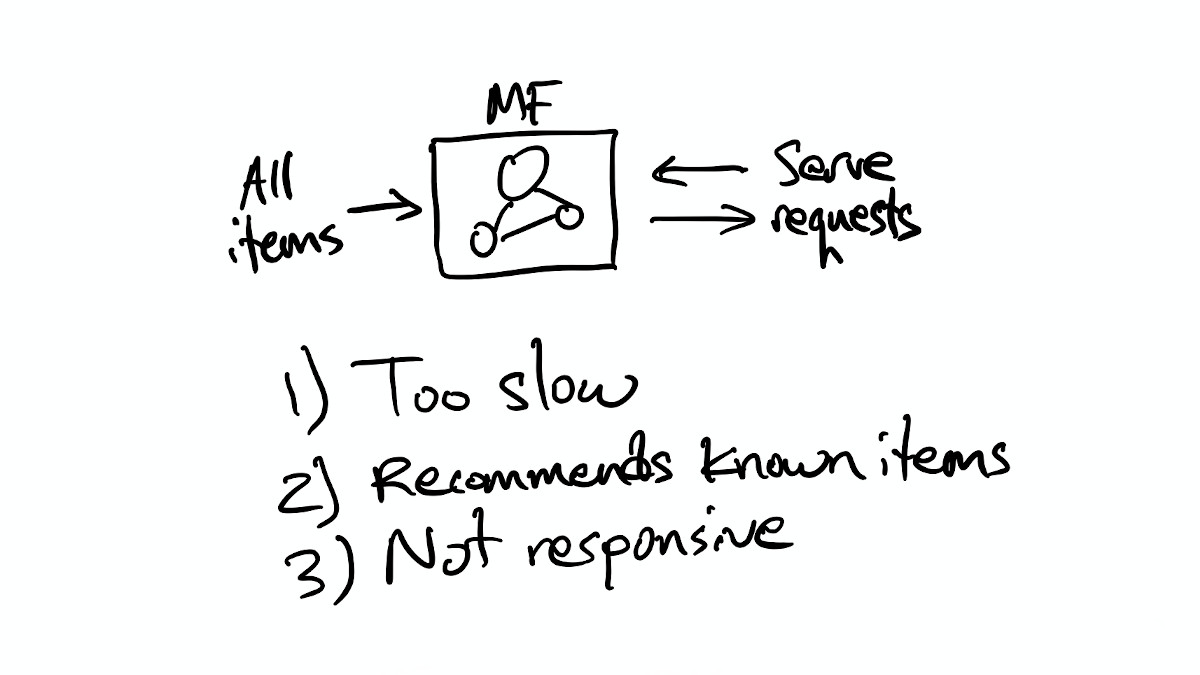
Latency
If we build a simple service around our model and try to use it to serve requests, we'll quickly discover that computing scores for all the items in our catalog is too slow to do in the request/response cycle. The recommendations are also quite likely to contain items that users have already seen, liked, or rated. (What's more similar to an item than itself?) And we'll also quickly realize that we have to retrain the model in order to generate new recommendations based on recent user behavior. Maybe we'll decide to retrain the model on a daily basis so that the recommendations stay fresh, but we won't be able to update the recommendations within a user's session to immediately respond to their actions.
Taking one problem at a time, the first obvious thing to do is move computing recommendations out of the request/response cycle and pre-compute them instead. Maybe we compute recommendations in a batch job and output them to a key/value store:
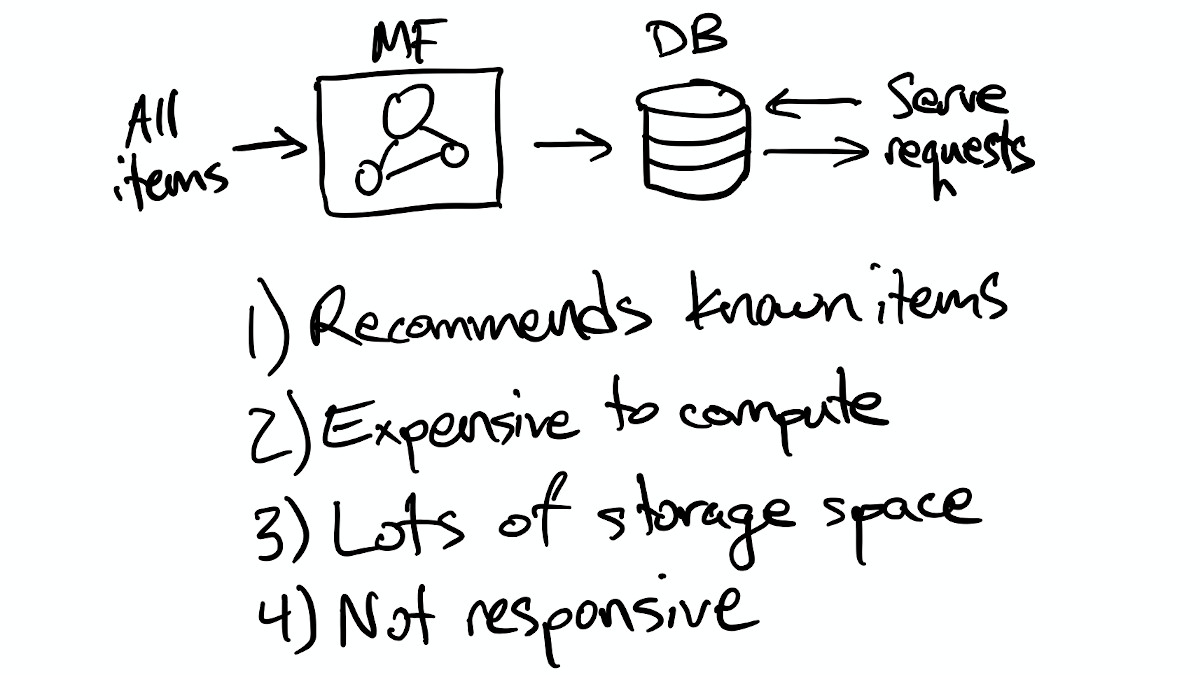
Now we have some new problems, because the batch job that computes recommendations for all users takes quite a bit of computing power, and the output from the job is potentially quite large (# users * # recommended items). Beyond the sheer cost of computing recommendations this way, most of the computation and storage is likely wasted, because we don't know which users will see the recommendations on a given day, so we have to compute fresh recommendations for all users every day.
But again, taking one problem at a time, it's easy enough to insert some filtering into the batch job to filter out any items a user has previously interacted with, which improves the user experience a bit.
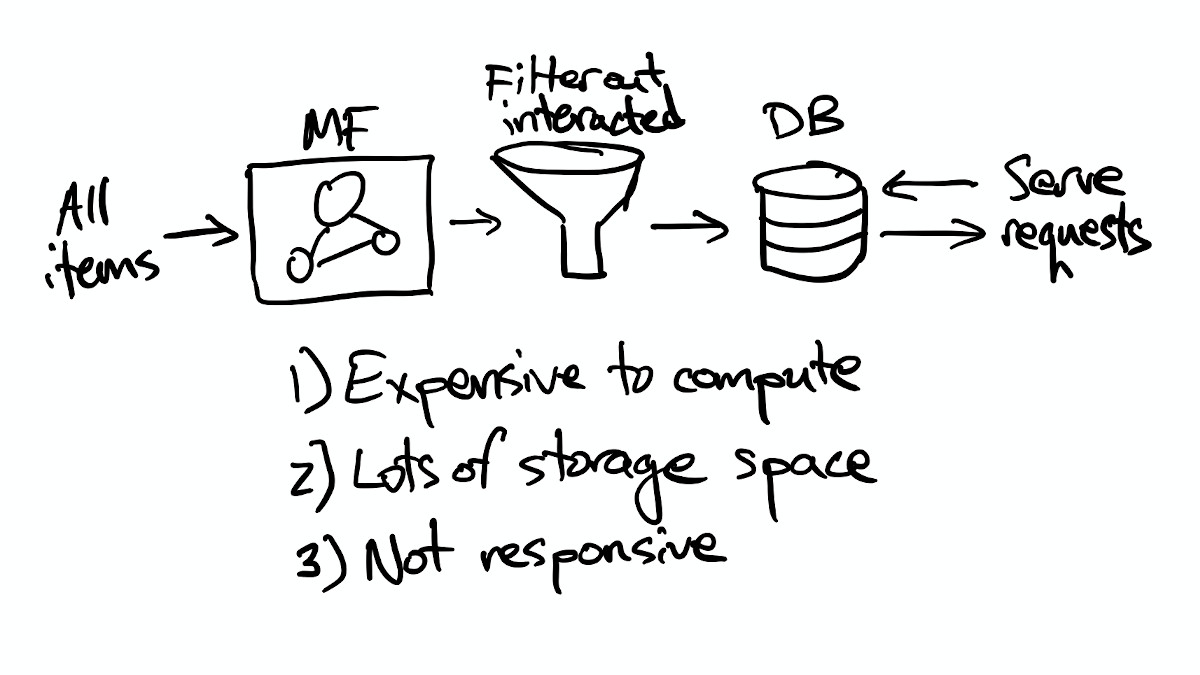
Candidate Selection
Thinking about how we can reduce the cost of computing recommendations, it's clear that most items in the catalog won't be relevant to most users, so we're wasting a lot of computing power scoring items that are highly unlikely to end up being recommended. There are two simple steps we can take:
- We can filter out items that have already been interacted with before we compute scores. (There's no point in computing scores for items we know won't be recommended, right?)
- We can limit the set of items we compute scores for by considering a smaller, personalized set of candidate items for each user (assuming we can find a cheap way to pick candidates.)
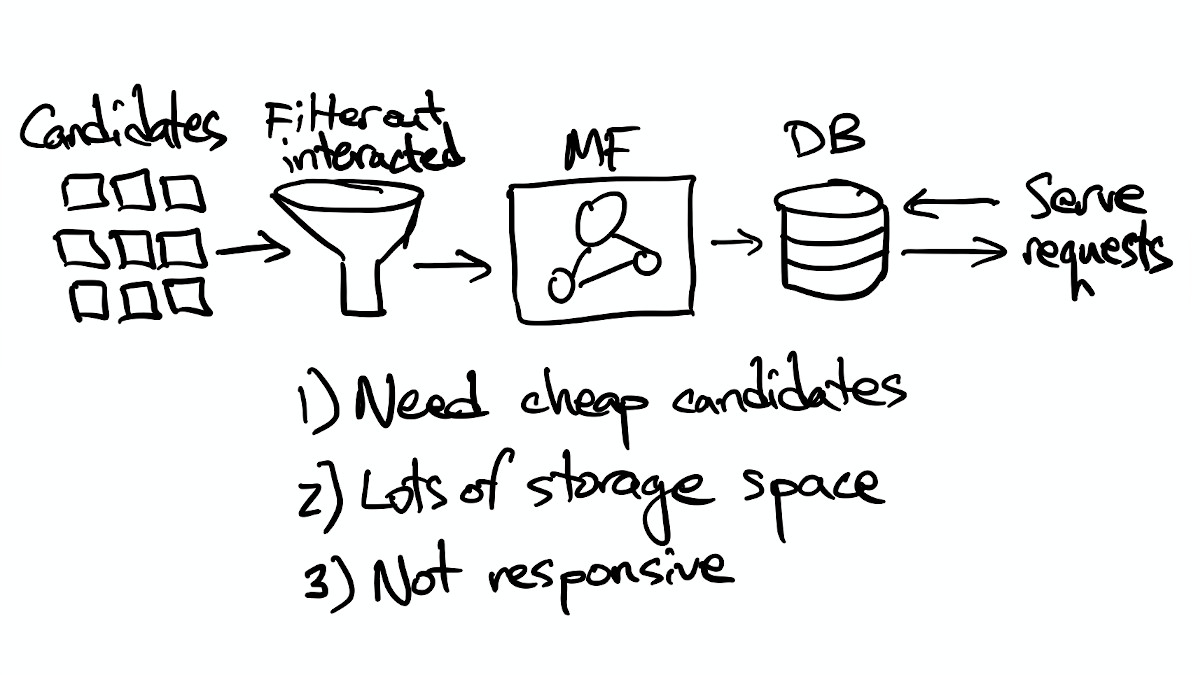
One cheap way to select candidate items is to compute how often items occur together in the same user history. We can compute co-occurrences with a batch job, and store a list of co-occurring items for each item in the catalog in a database (again, perhaps a key/value store.) Now when we want to select candidate items for a particular user, we look up what items that user has interacted with previously, find the co-occurring items for each one, and only use our model to compute scores for that limited candidate set.
This solves multiple problems:
- It takes less storage space, since the number of users is typically much larger than the size of the item catalog. We've reduced the storage space requirements from (# users * # recommended items) to (# items * # stored co-occurrences).
- It allows us to be more responsive, because using a limited set of candidates makes it much faster to fetch, filter, and score them. That means we can stop pre-computing everyone's recommendations (which is great!), but it also means that the candidate set changes a little bit every time we record a new user interaction with an item.
Now, the system looks like this:
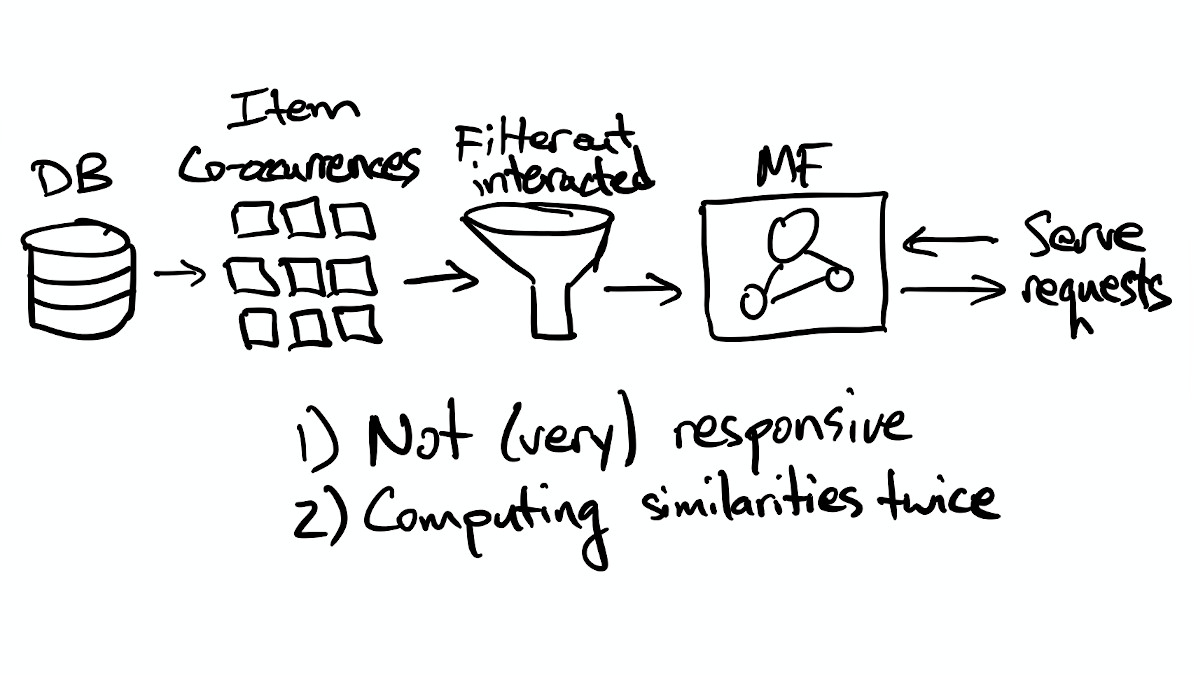
That's a little bit better, but we still have the issue our model only updates its user representations when it's re-trained. We're also implicitly computing item-to-item similarities two different ways, because we're both computing item co-occurrences to find candidate items and learning item embeddings in the model.
People Change And That's Okay
To improve the responsiveness of our model, we could try to train it online so that it updates user vectors every time a new interaction is logged, but there's an easier way: we can compute user vectors as sums of the item vectors for the items that users interacted with.
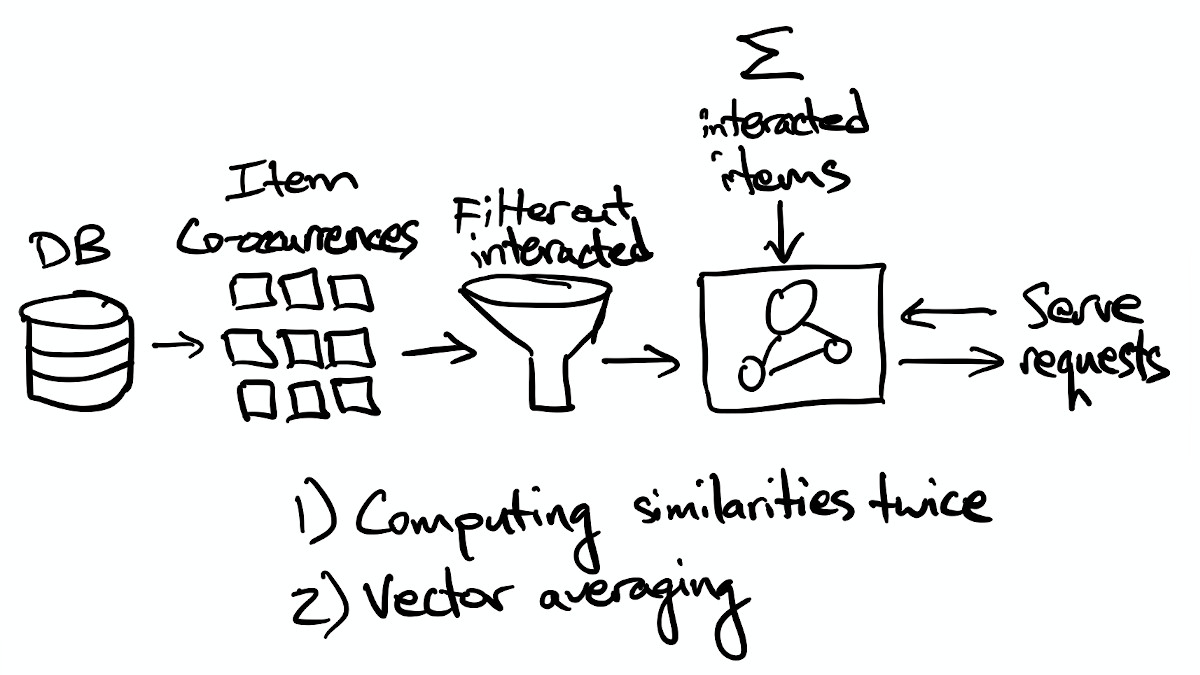
Yes, this means we're completely throwing away the user vectors learned by the model, which might mean we lose a bit of accuracy. That has significant advantages, though:
- We can compute a user vector for a new user immediately as soon as they interact with any item. We still have a cold-start problem, but we've mitigated it quite a bit.
- We no longer have to train with all the data we have on hand, because it's less important that every user is individually included in the training data. (What matters now is that we make sure the training data covers all the items.)
- We're not tied to matrix factorization at this point; we can use any model that's capable of generating item embeddings from interaction data (e.g. word2vec.)
So that's better in some ways, but (of course) it also introduces new problems. If we're summing or averaging item vectors to produce user vectors, we're assuming that a user's tastes can be represented as a single point in the item space, which is a pretty limited representation. There's no guarantee that any particular user only likes one kind of item; in fact, that is probably a far rarer case than users who like many kinds of items. Vector averaging also produces weird results sometimes, since there's no guarantee that the point halfway between two different kind of items is semantically meaningful. It might represent items that are blend of the two, or it might represent something else entirely. (In practice, it usually works okay, but there are definitely exceptions.)
What can we do to stop computing redundant item similarities? Well, we could use the item vectors from our model to retrieve candidates with approximate nearest neighbor search. To do that, we'd load all of the item vectors into ANN search index, and query it with our (aggregated) user vectors:
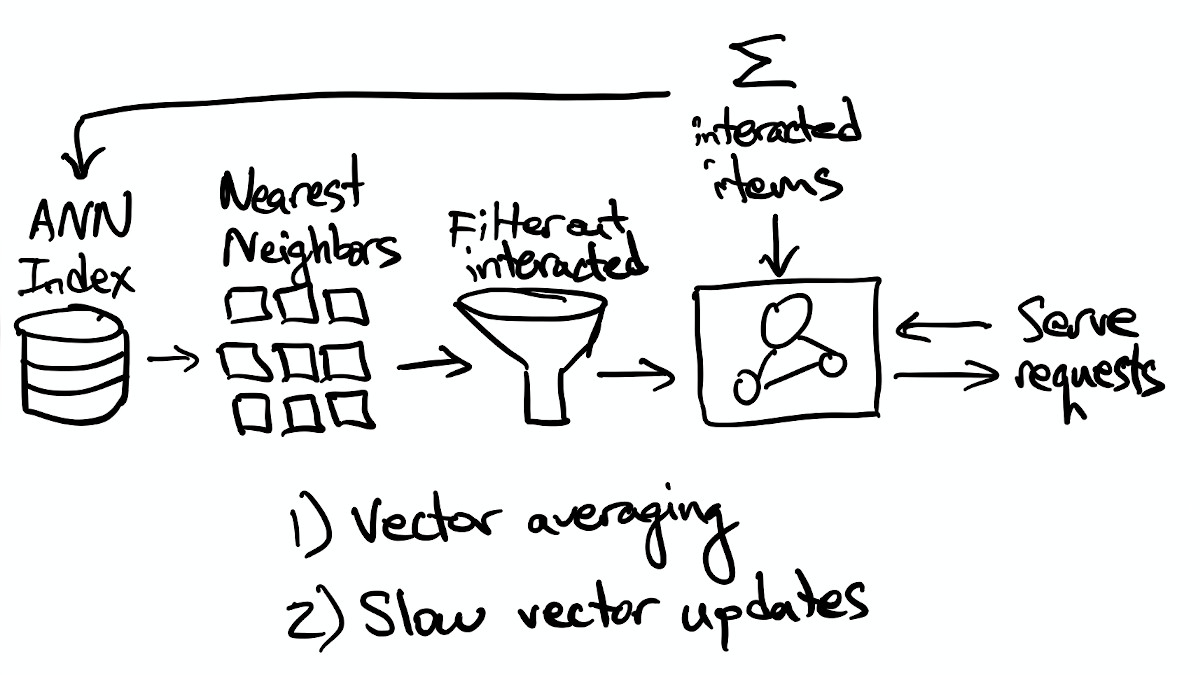
Now we get a list of candidate items for each user that are similar to the average of the other items they've interacted with, we filter out any exact matches with their interaction history, we assign a score to each remaining item, and we use those scores to determine which items to recommend and what order to put them in. We no longer need a batch job to compute item co-occurrences, but we will need to extract item vectors from the model and load them into an ANN index.
There are still some lingering issues from the process of aggregating item vectors into user vectors though, so let's see what we can do about those:
- We can mitigate the potential impact of weird results from vector averaging by performing a bulk look-up from the ANN search index with the list of items the user has interacted with. That makes the candidates more directly similar to previously interacted items (instead of their average.)
- We can mitigate user vectors that change very slowly as users' interaction histories get longer either by imposing a time window (e.g. interactions from the last N months) or by computing a weighted average that weights more recent interactions more heavily. (Or both.)
Go Forth And Build Recommender Systems
That takes us from a freshly trained model to a system that's capable of generating fresh recommendations for each user on-the-fly as requests come in. There's still a lot of room to improve this system, but you'd be surprised how many industrial recommender systems work like one of the pictures above.
If you found this useful, consider supporting my coffee consumption? :)

Comments !